Unveiling the Power of Drizzle ORM: Key Features that Skyrocketed My Productivity
Want to supercharge your dev productivity? Get a glimpse into how Drizzle ORM, with its well-structured docs and powerful features, could be a game-changer for your projects.
Inspired by a few of my favorite tech YouTubers, namely Theo and Josh, I was intrigued to try out Drizzle ORM after hearing their rave reviews. Having since incorporated Drizzle into several projects, I've discovered numerous features that have not only enhanced my productivity but have also made the development process more enjoyable. Want to know why Drizzle has made such a difference? Stay with me as I dive into its game-changing features.
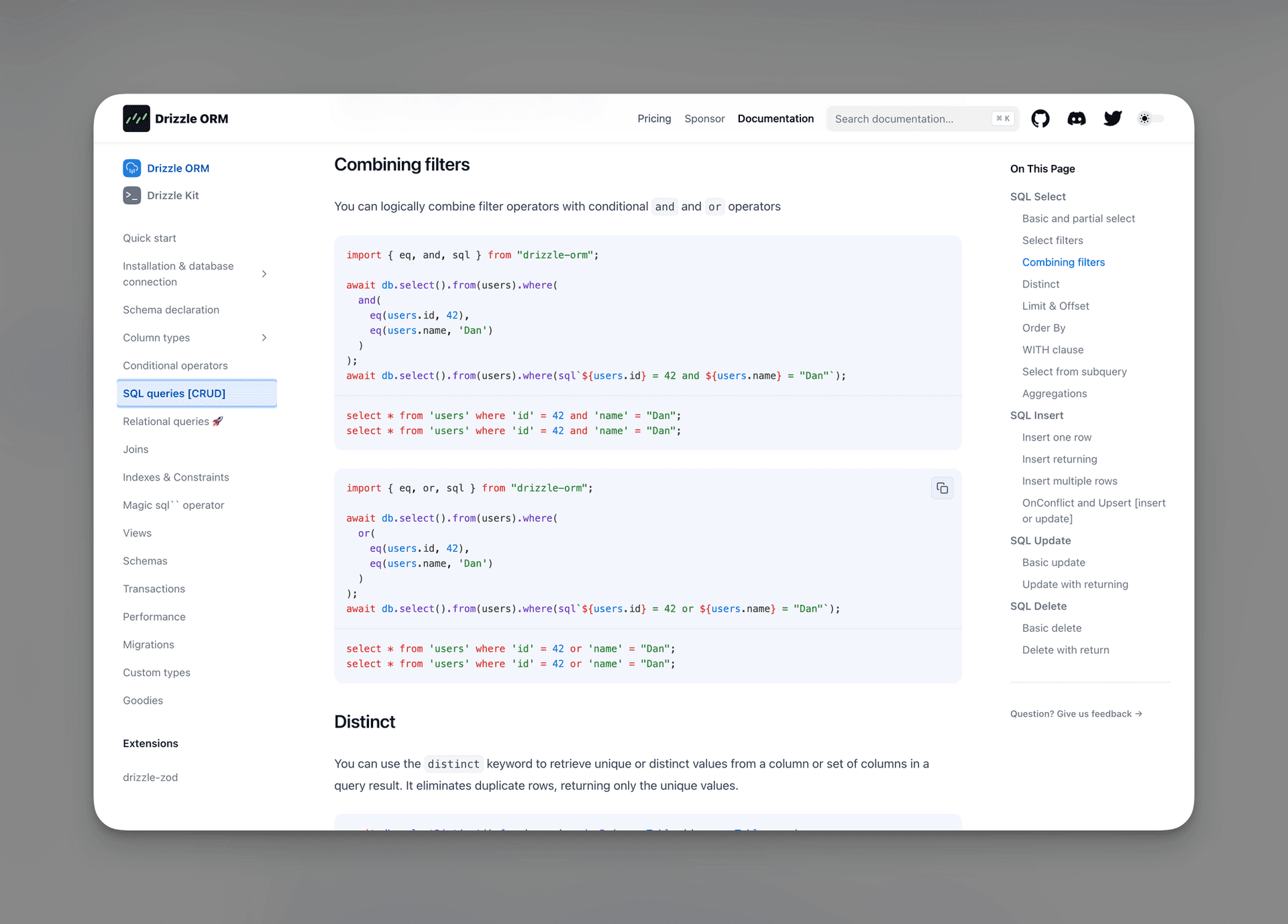
Beyond the very funny marketing landing page (see blogpost cover), Drizzle also finally launched a highly anticipated documentation. What I particularly like is that the documentation is well structured and broken down logically.
First there is Drizzle ORM:
Drizzle ORM is a TypeScript ORM for SQL databases designed with maximum type safety in mind.
And then there is Drizzle Kit :
Drizzle Kit - is a CLI companion for automatic SQL migrations generation and rapid prototyping
For each of these they have the most important topics displayed nicely in a sidebar on the left, and then a table of contents for this particular page on the right sidebar.
When adopting a relatively new library, it can be a struggle to remember the specific API syntax. If you know SQL though, you already know Drizzle.
The ORM's main philosophy is "If you know SQL, you know Drizzle ORM". We follow the SQL-like syntax whenever possible, are strongly typed ground up, and fail at compile time, not in runtime.
"While most ORMs manage to handle the simpler examples adequately, Drizzle takes it a step further. It truly excels in dealing with complex TypeScript joins, navigating terrain where many others struggle. Moreover, Drizzle shines by offering advanced database features, such as transactions, thereby enhancing its functionality and flexibility
In the following there's a real life query from one of my projects, that has a lot of conditions, filters and all sort of things going on that I use for server side filtered table:
export async function getTournaments({ userId, timeframe = undefined, limit = undefined, sort = 'asc', from = undefined, to = undefined, organizerId = undefined, eventId = undefined, minBuyIn = undefined, maxBuyIn = undefined, minGuarantee = undefined, maxGuarantee = undefined,}: { userId: string timeframe?: string limit?: number sort?: 'asc' | 'desc' from?: string to?: string organizerId?: string eventId?: string minBuyIn?: number maxBuyIn?: number minGuarantee?: number maxGuarantee?: number}) { const now = new Date().toUTCString() let query = db .select({ tournamentId: tournaments.id, tournamentStartAt: tournaments.startAt, organizerName: organizers.name, organizerId: organizers.id, eventName: events.name, eventId: events.id, tournamentName: tournaments.name, buyIn: tournaments.buyIn, tournamentGuarantee: tournaments.guarantee, buyInCurrency: buyInCurrency.symbol, guaranteeCurrency: guaranteeCurrency.symbol, userId: userTournaments.userId, }) .from(tournaments) .leftJoin(events, eq(tournaments.eventId, events.id)) .leftJoin(organizers, eq(events.organizerId, organizers.id)) .leftJoin(buyInCurrency, eq(tournaments.buyInCurrencyId, buyInCurrency.id)) .leftJoin(guaranteeCurrency, eq(tournaments.guaranteeCurrencyId, guaranteeCurrency.id)) .leftJoin(userTournaments, eq(tournaments.id, userTournaments.tournamentId)) if (limit) query = query.limit(limit) if (sort === 'desc') query = query.orderBy(desc(tournaments.startAt)) if (sort === 'asc') query = query.orderBy(asc(tournaments.startAt)) let whereCondition if (timeframe === 'my-tournaments') { whereCondition = eq(userTournaments.userId, userId) } else if (timeframe === 'upcoming') { whereCondition = and( isNotNull(tournaments.startAt), gte(tournaments.startAt, now), isNull(userTournaments.userId), ) } else if (timeframe === 'past') { whereCondition = and( isNotNull(tournaments.startAt), lt(tournaments.startAt, now), isNull(userTournaments.userId), ) } else { whereCondition = isNotNull(userTournaments.userId) } // Add from and to filters if (from && to) { const fromDate = new Date(from).toISOString() const toEndOfDay = new Date(to) toEndOfDay.setHours(23, 59, 59, 999) const toDate = new Date(to) toDate.setHours(23, 59, 59, 999) whereCondition = and( whereCondition, between(tournaments.startAt, fromDate, toDate.toISOString()), ) } // Add filter for organizerId if (organizerId) { whereCondition = and(whereCondition, eq(organizers.id, Number(organizerId))) } // Add filter for eventId if (eventId) { whereCondition = and(whereCondition, eq(events.id, Number(eventId))) } // Add filter for minBuyIn if (minBuyIn) { whereCondition = and(whereCondition, gte(tournaments.buyIn, minBuyIn.toString())) } // Add filter for maxBuyIn if (maxBuyIn) { whereCondition = and(whereCondition, lte(tournaments.buyIn, maxBuyIn.toString())) } // Add filter for minGuarantee if (minGuarantee) { whereCondition = and(whereCondition, gte(tournaments.guarantee, minGuarantee.toString())) } // Add filter for maxGuarantee if (maxGuarantee) { whereCondition = and(whereCondition, lte(tournaments.guarantee, maxGuarantee.toString())) } query = query.where(whereCondition) // console.log(query.toSQL()) const data = await query return data}
With all of this complicated logic Drizzle still gives me perfect type annotations.
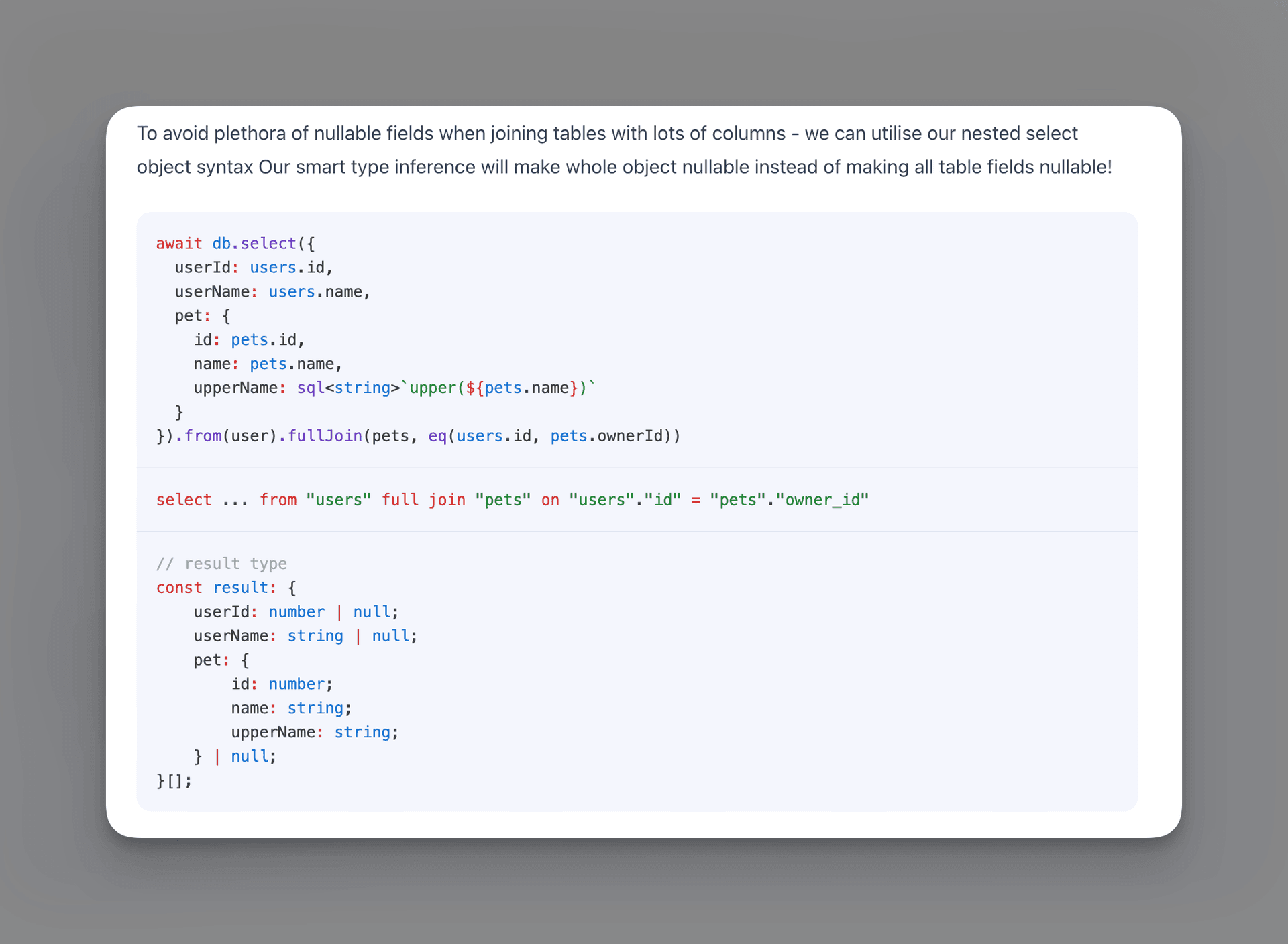
Even with partial select, when you expect any joined table to be potentially have null types for every field, Drizzle shines:
When I work with a relational database, I normalize my tables and keep everything neatly organised. However, this approach can introduce complexities when it comes to populating these tables. Let's explore this issue using a practical example from my SaaS, BacklinkGPT.com.
In the process of creating a record for my campaign backlink prospect table, a sequence of insertions must take place first. Here are the necessary steps:
Insert the website into the websites table of a and get the corresponding id to link it to a backlink prospect
Insert the contact into the contacts table and get the corresponding id to link it to the backlink prospect
Insert the backlink prospect with the just inserted website_id , contact_id and other backlink prospect info
Finally, insert the backlink_prospect_id as well as the campign_id to finally get the campaign_backlink_prospect_id
Being a big fan of Supabase, I tried to do this first with the Supabase SDK and wasn't happy with the implementation. However, the implementation fell short of my expectations. Whenever an insert operation failed, I found myself writing extensive logic to undo the changes.
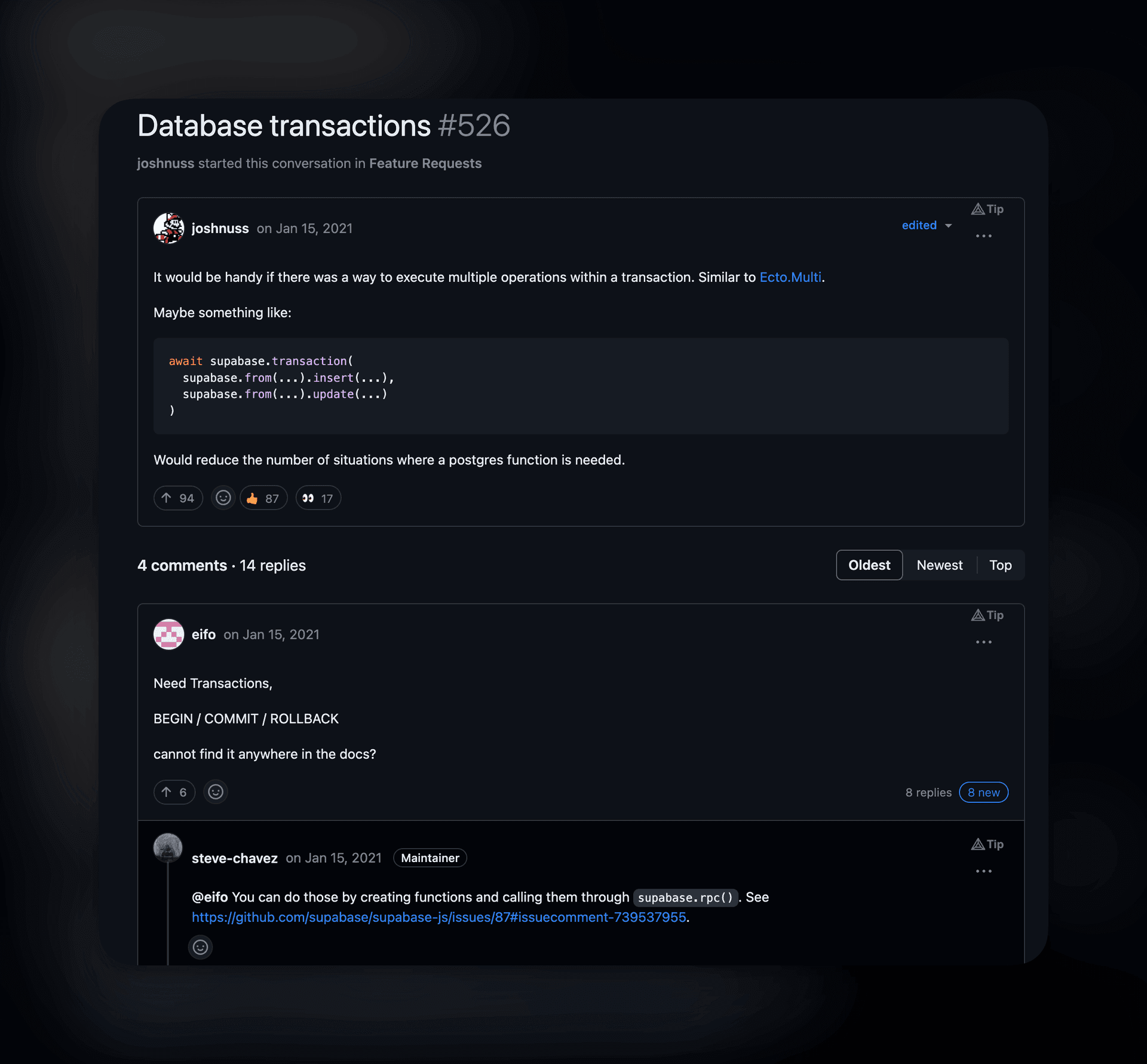
What would truly solve this issue is the ability to use transactions to manage these operations:
SQL transaction is a grouping of one or more SQL statements that interact with a database. A transaction in its entirety can commit to a database as a single logical unit or rollback (become undone) as a single logical unit.
Unfortunately, as of now you can only do this with Supabase by calling a supabase function with the .rpc method. While this could technically be a great solution, I did not like to have this complex logic stored in a postgres function with no version control.
Luckily, Drizzle ORM supports transactions, and it was quite easy to implement with their excellent docs:
By far this is my favourite feature, as it makes you so much more productive as a developer. The power behind Drizzle reminds me a bit about Theo's video:
Every Developer will eventually have some sort of similar workflow for inserting data into a table:
Create a table with schema.
Create a zod model for input parsing and type-safety based on form table requirements.
Derive types from zod model and pass types and schema to e.g. react-hook-form resolver.
Extend or modify zod schema to match real table schema before inserting.
All of this is super manual, error prone and very annoying especially if you make schema changes and you have to manually adjust everything.
Drizzle solves all of these issues perfectly with the drizzle-zod plugin.
Notice how I can even refine the schema on the fly to make the uderId and id optional just for
react-hook-form as I want to provide those automatically in my server action.
I can then create my server action function and easily pass in all the data, while getting reminded from the onboardingSurveys types to provide still my id , userId and createdAt :
export async function saveOnboardingSurvey({ data,}: { data: TForm}) { 'use server' const { userId } = auth() if (!userId) throw new Error('User not found') await db.insert(onboardingSurveys).values({ ...data, userId, createdAt: new Date(), })
Reuse of drizzle-zod schema.
Building forms and moving types and schemas between client and server components has never been so easy and fun!
When I initially considered Drizzle, I was a bit skeptical. I anticipated a lot of effort in creating a complete schema to get typings for my existing Supabase project. However, I was pleasantly surprised - all it took was a single command and voila, my types were ready:
drizzle-kit generate:pg --custom
drizzle-kit introspect:{dialect} command lets you pull DDL from existing database and generate schema.ts file in matter of seconds.
With this feature you can really test the waters before committing fully.
Just after one month of launching Relational Queries the Drizzle team launched a database-browser kit for the Drizzle ecosystem.
Though it's still in beta and undergoing continuous development, I am thoroughly excited about utilizing a GUI for inspecting and editing data. I have been using the PostgreSQL Explorer VS Code extension, which is excellent in its own right, but lacks the ability to edit data directly.
But, in the interest of giving you the full picture, I'll also share a few areas where Drizzle might not be perfect yet and where I stumbled upon some challenges.
The drizzle team recently released the drizzle-kit push:pg command. Here's the when to use it:
When do you need to use the 'push' command?
During the prototyping and experimentation phase of your schema on a local environment.
Whenyou are utilizing an external provider that manages migrations and schema changes for you
(e.g., PlanetScale).
If you are comfortable modifying the database schema before your code changes can be deployed.
If you wanna see first the migrations and then push them to the DB without having to copy and manually
execute all the statements, I came up with these scripts:
"scripts": { "dev": "pnpm next dev", "build": "pnpm next build && pnpm generate && pnpm push", "start": "pnpm next start", "lint": "pnpm next lint", "generate": "drizzle-kit generate:pg --config=drizzle.config.ts", "update-pg": "drizzle-kit up:pg --config=drizzle.config.ts", "check": "drizzle-kit check:pg --config=drizzle.config.ts", "drop": "drizzle-kit drop --config=drizzle.config.ts", "push": "node -r dotenv/config -r ts-node/register src/migrate.ts"},
So if someone's struggling like me, I hope this is helpful.
If you found this post helpful and are eager for more insights like this, don't hesitate to follow me on Twitter and subscribe to my newsletter. That way, you'll be the first to know when I share new tips, tools, and insights to boost your productivity as a developer.
And, if you're about to dive into Drizzle, I'd love to hear about your experiences.